Ensemble Methods and Boosting
Bagging & Boosting · Ensemble Learning · Model Performance
Overview
This project explores classic and ensemble-based classification methods with a strong focus on model optimization and recall improvement. Built around practical classification problems, it applies baseline models, tree ensembles, and boosting algorithms while incorporating class balancing strategies and hyperparameter tuning.
The project reflects a real-world data science workflow—from baseline evaluation to iterative performance improvements.
Technology Stack
- Programming Language:
Python - Libraries:
scikit-learn, matplotlib, seaborn, NumPy, pandas - Tooling:
Jupyter Notebook, GridSearchCV, confusion matrix plotting
Methodology
and Approach
1. Baseline Classifiers and Evaluation
- Built standard models: Gaussian Naive Bayes, K-Nearest Neighbors (KNN), and Logistic Regression.
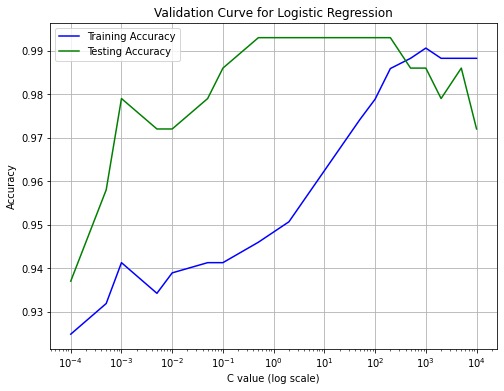
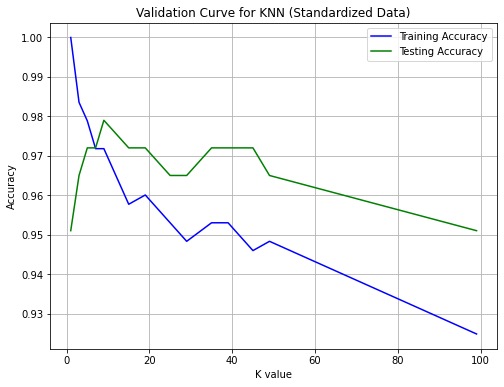
- Performed validation curve analysis to examine sensitivity to hyperparameters (C in logistic regression, k in KNN).
- Explored the impact of standardization on model performance and learning curves.
2. Tree-Based Models and Bagging
- Trained Decision Tree and Random Forest classifiers.
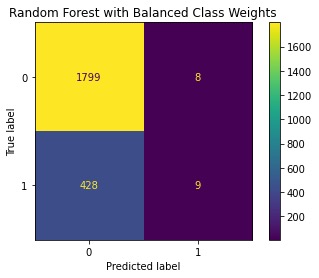
- Evaluated model performance using accuracy, recall, and balanced accuracy, with confusion matrix visualization.
- Introduced class_weight=”balanced” to handle class imbalance.
3. Boosting and Ensemble Optimization
- Applied AdaBoost and Gradient Boosting classifiers.
- Conducted multi-stage Grid Search to fine-tune n_estimators and learning_rate.
- Selected models based on recall improvement for the minority class (positive cases).
- Performed comparative evaluation between bagging and boosting to highlight trade-offs in interpretability and performance.
4. Performance Tuning and Model Selection
- Used GridSearchCV with cross-validation to find optimal hyperparameters for each model.
- Compared models not only by accuracy, but also by recall, F1-score, and balanced accuracy, which is critical for imbalanced datasets.
- Justified final model choices based on both metrics and error type considerations.
Results & Insights
- Logistic Regression showed sensitivity to the regularization parameter C; standardization significantly improved learning curves.
- Random Forest with balanced class weights increased recall compared to standard trees.
- Gradient Boosting, after careful tuning, achieved the highest recall for the positive class while maintaining balanced accuracy.
- The project demonstrated that model performance is only as good as the tuning strategy, and class imbalance requires deliberate metric selection.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Access Full Details and Files
For full project details, source files, and additional insights, visit the GitHub repository.