Test-Time Training — Is It an Alternative to Transformer?
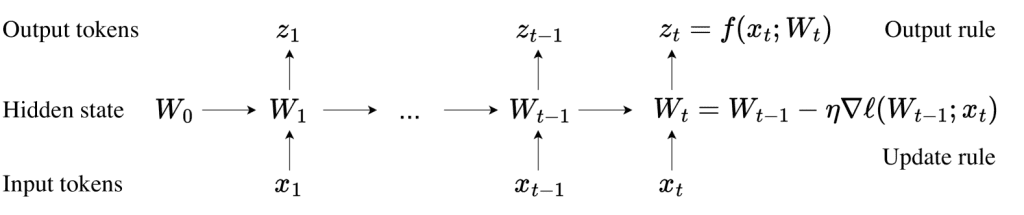
This research paper shows that TTT-Linear outperforms Mamba and Transformer in handling contexts as long as 32k. (See the card below) A self-supervised loss function on each test sequence reduces the likelihood of information forgetting in long sequences. Will the Test-Time Training(TTT) solve the problem of forgetting information in long sequences? As for the algorithm:
Test-Time Training — Is It an Alternative to Transformer? Read More »
Research Highlights