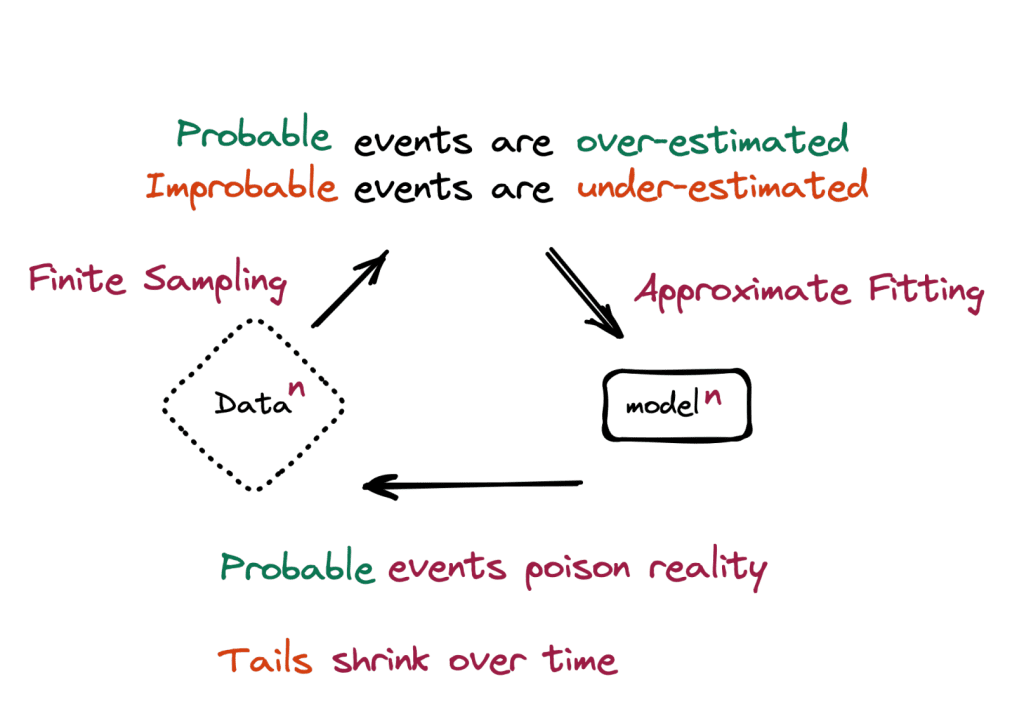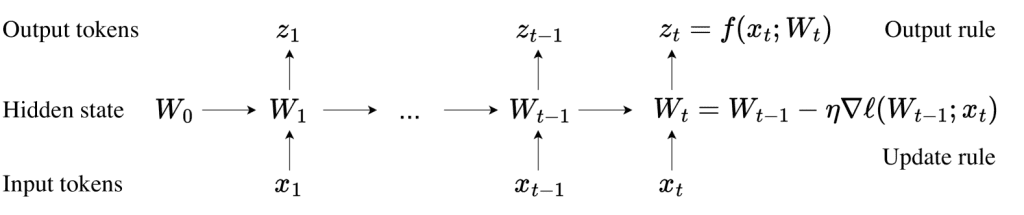
This research paper shows that TTT-Linear outperforms Mamba and Transformer in handling contexts as long as 32k. (See the card below) A self-supervised loss function on each test sequence reduces the likelihood of information forgetting in long sequences.
Will the Test-Time Training(TTT) solve the problem of forgetting information in long sequences?
[2407.04620] Learning to (Learn at Test Time): RNNs with Expressive Hidden States
As for the algorithm:
The following explains their motivation to solve distribution drifts and ingenious ways of constructing the Test-Time Training algorithm with self-supervision.