Regression and Clustering
Predictive Models · Unsupervised Learning · Pattern Discovery
Overview
This project showcases foundational machine learning techniques applied to real-world tasks, including regression modeling, document clustering, and image classification.
By combining both self-implemented and scikit-learn-based models, the work emphasizes algorithmic understanding, interpretability, and the importance of preprocessing in model performance.
Technology Stack
- Programming Language:
Python - Libraries:
pandas, matplotlib, scikit-learn, WordCloud, seaborn - Tools:
Jupyter Notebook
Methodology
and Approach
1. Regression Modeling
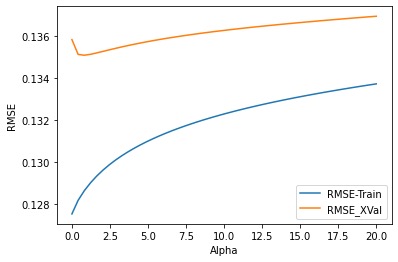
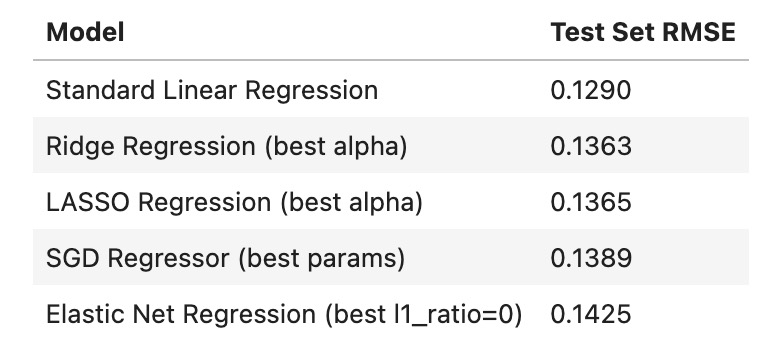
- Manually implemented standard linear regression, Ridge, and LASSO from scratch using NumPy.
- Designed reusable functions for alpha tuning and RMSE evaluation.
- Compared performance with sklearn equivalents and used 10-fold cross-validation for fair benchmarking.
2. Document Clustering with Custom Distance
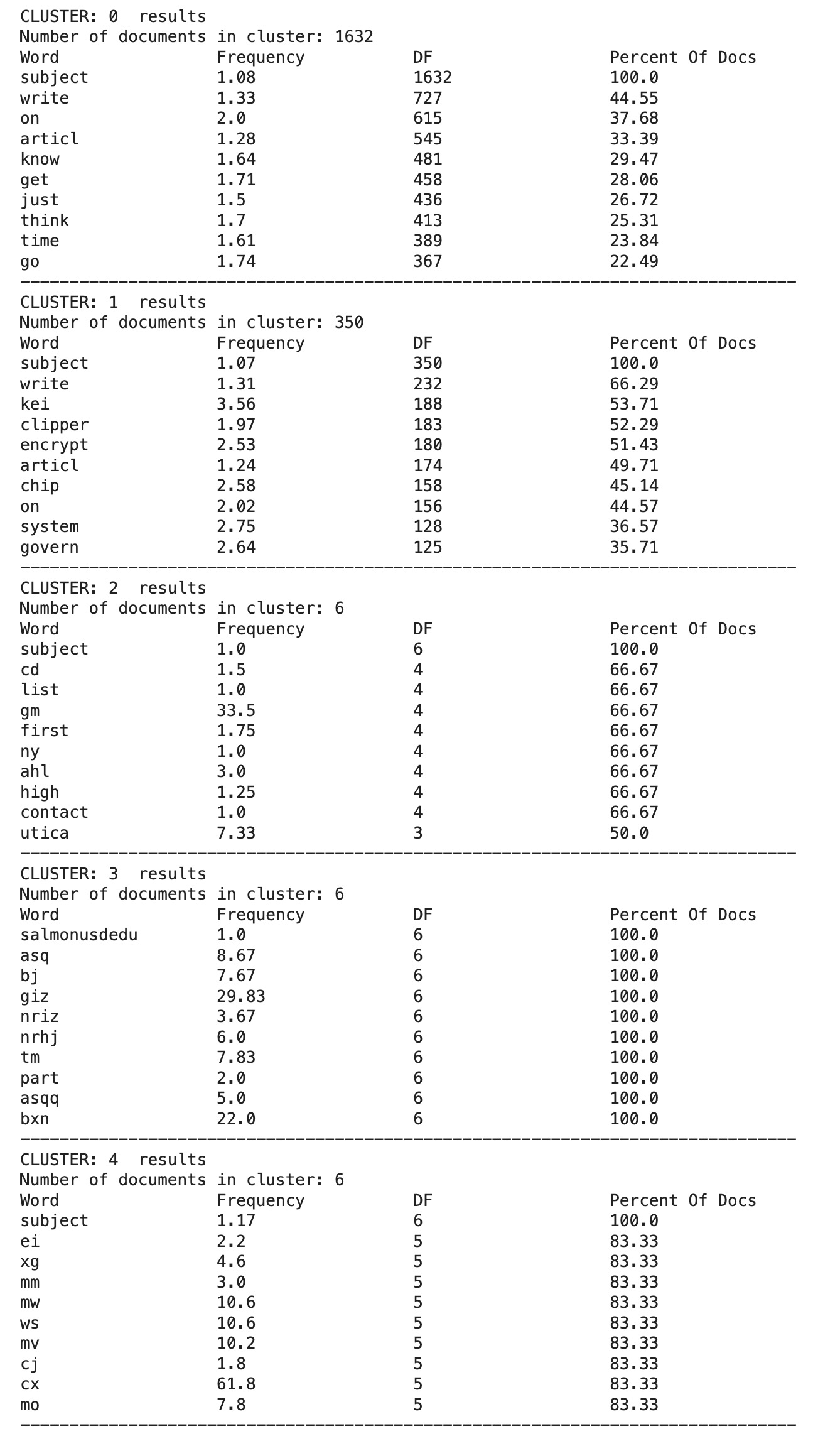
- Performed KMeans clustering using a custom cosine similarity distance function, replacing the default Euclidean metric.
- Extracted top terms per cluster using document frequency (DF%) and sorted them for interpretability.
- Generated visualizations via WordCloud to intuitively reflect cluster semantics.
3. PCA and Image Clustering
- Applied dimensionality reduction via PCA to image datasets, followed by clustering.
- Compared clustering performance (completeness & homogeneity) before and after PCA, illustrating the benefits of preprocessing.
- Demonstrated that PCA improved cluster separation with minimal information loss.
4. Integrated Presentation and Evaluation
- All models include visual evaluation (scatter plots, WordClouds, confusion matrices).
- Summarized key performance metrics in tables and plots for quick comparison.
- The structure emphasizes not just model building, but also communication and analysis clarity—a key skill in applied data science.
Results & Insights
- Manual models achieved performance close to sklearn baselines, validating correct implementation.
- The use of cosine similarity significantly improved document clustering alignment with actual categories.
- PCA improved the completeness score in image clustering from 61% to 65%, with homogeneity staying consistent.
- Demonstrated the importance of distance metric selection, dimensionality reduction, and clear performance tracking in real ML workflows.


Access Full Details and Files
For full project details, source files, and additional insights, visit the GitHub repository.