In traditional Transformer architectures, the computational complexity grows quadratically (O(L²)) with the length of the sequence, making it resource-intensive to process long sequences. This high demand for resources makes it impractical to extend context length directly. Even when fine-tuned on longer sequences, LLMs often struggle with extrapolation, failing to perform well on sequences longer than during training. Moreover, obtaining high-quality long-text datasets is a significant challenge, further complicating the training process.
Some existing methods attempt to address this by modifying attention mechanisms or compressing tokens to manage extremely long sequences. While these approaches may maintain low perplexity, they often fall short in tasks that require deep comprehension of long texts, such as information verification and question answering, where models frequently fail to grasp the full context.
To address these challenges, Tsinghua University and Xiamen University researchers have developed a new framework called FocusLLM, designed to extend the context length of large language models (LLMs) through a parallel decoding mechanism.
🔍 The Core Idea:
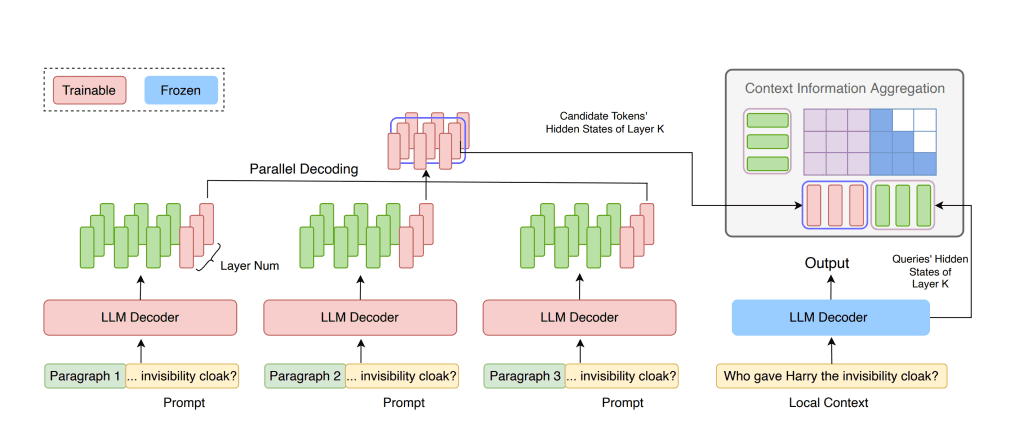
FocusLLM processes long texts by dividing them into chunks based on the model’s original context length. It then uses parallel decoding to extract key information from each chunk, integrating this information into the local context. This innovative approach transforms long-text prediction into a process where candidate tokens from multiple chunks are generated simultaneously and aggregated into memory to produce the final token.
💡 Performance & Efficiency:
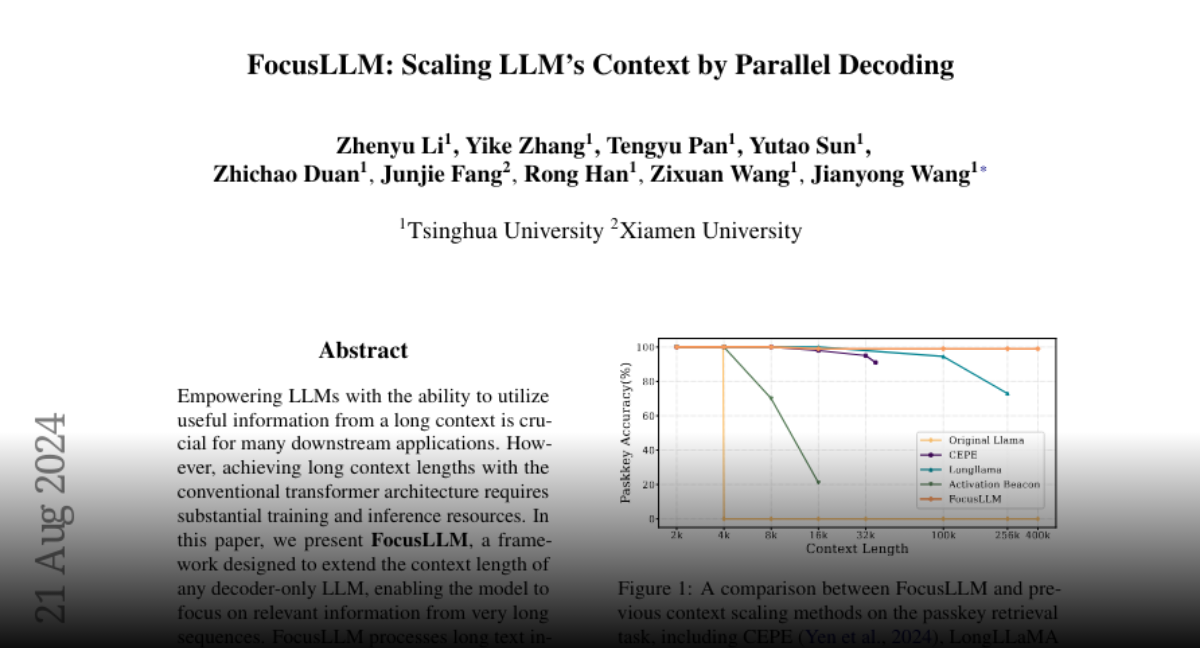
FocusLLM stands out in training efficiency and versatility. With minimal training cost, it maintains strong language modeling capability and downstream task performance even when handling extremely long texts (up to 400K tokens). In various benchmarks, FocusLLM excels, especially in tasks involving ultra-long contexts, significantly outperforming other context extension methods like CEPE and LongLLaMA.
🌟 Key Features:
• Context Extension: Breaks traditional positional limitations, allowing the model to handle texts that are tens or even hundreds of times longer.
• Training Efficiency: Retains original model parameters, adds only a small number of trainable parameters, and completes training with a minimal budget.
• Versatility: Excels in downstream tasks like question answering while maintaining low perplexity on long documents.
By applying FocusLLM to the LLaMA-2-7B model, researchers have validated its effectiveness across multiple tasks, showing that it surpasses existing context extension methods in both training efficiency and performance.