
The Crucial Challenge of OpenAI’s o1 Model And All of Us
Over the past day, countless people have excitedly participated in testing OpenAI’s o1.
The release of the new model has undoubtedly become an internet sensation. The leaks and hints surrounding “Strawberry” in the early stages, the increasingly competitive market environment, and the public’s focus on industry leaders have heightened attention toward the new model.
OpenAI, notably, did not follow the naming conventions of ChatGPT but assigned a new series number to this model, highlighting their emphasis on it. According to official statements, the o1 model is specifically trained for complex reasoning and has achieved an accuracy surpassing that of human Ph.D. levels in GPQA benchmark tests.
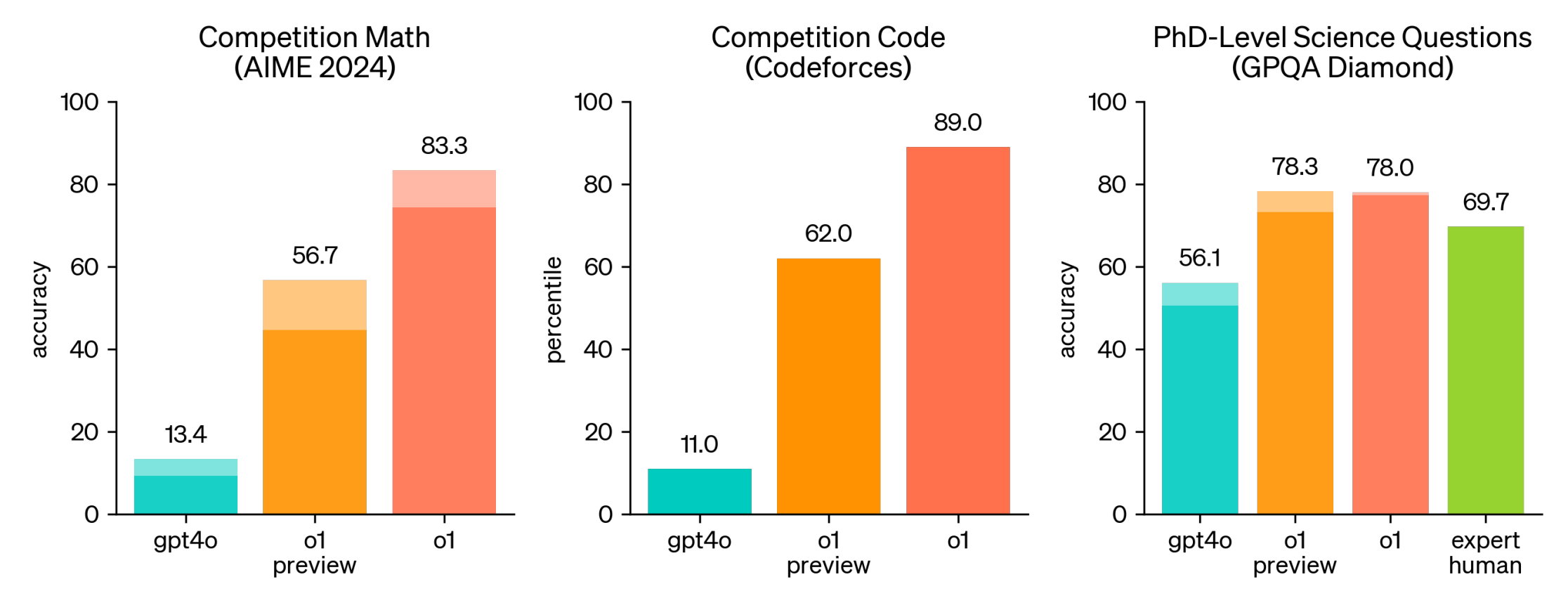
OpenAI claims that the training method of this model involves a new large-scale reinforcement learning technique and a prompt engineering method called Chain of Thought (CoT), which aims to guide language models to solve complex problems through step-by-step thinking. Like the reasoning process in the human brain, it breaks down problems into smaller, more manageable tasks to enhance performance in logic, computation, and decision-making tasks. Using step-by-step reasoning allows the model to more easily identify and correct errors in intermediate steps. Employing CoT also improves the interpretability of the model’s output, making it easier for users to understand the reasoning process inside the model.
However, based on feedback from many users, the current preview version has fallen short of expectations. Some professionals in the field have noted that the new model doesn’t fully live up to its marketing claims, particularly when it comes to achieving the advertised 64k context length. In fact, OpenAI has stated that “the o1-preview and o1-mini models offer a context window of 128,000 tokens.” in their API Doc.
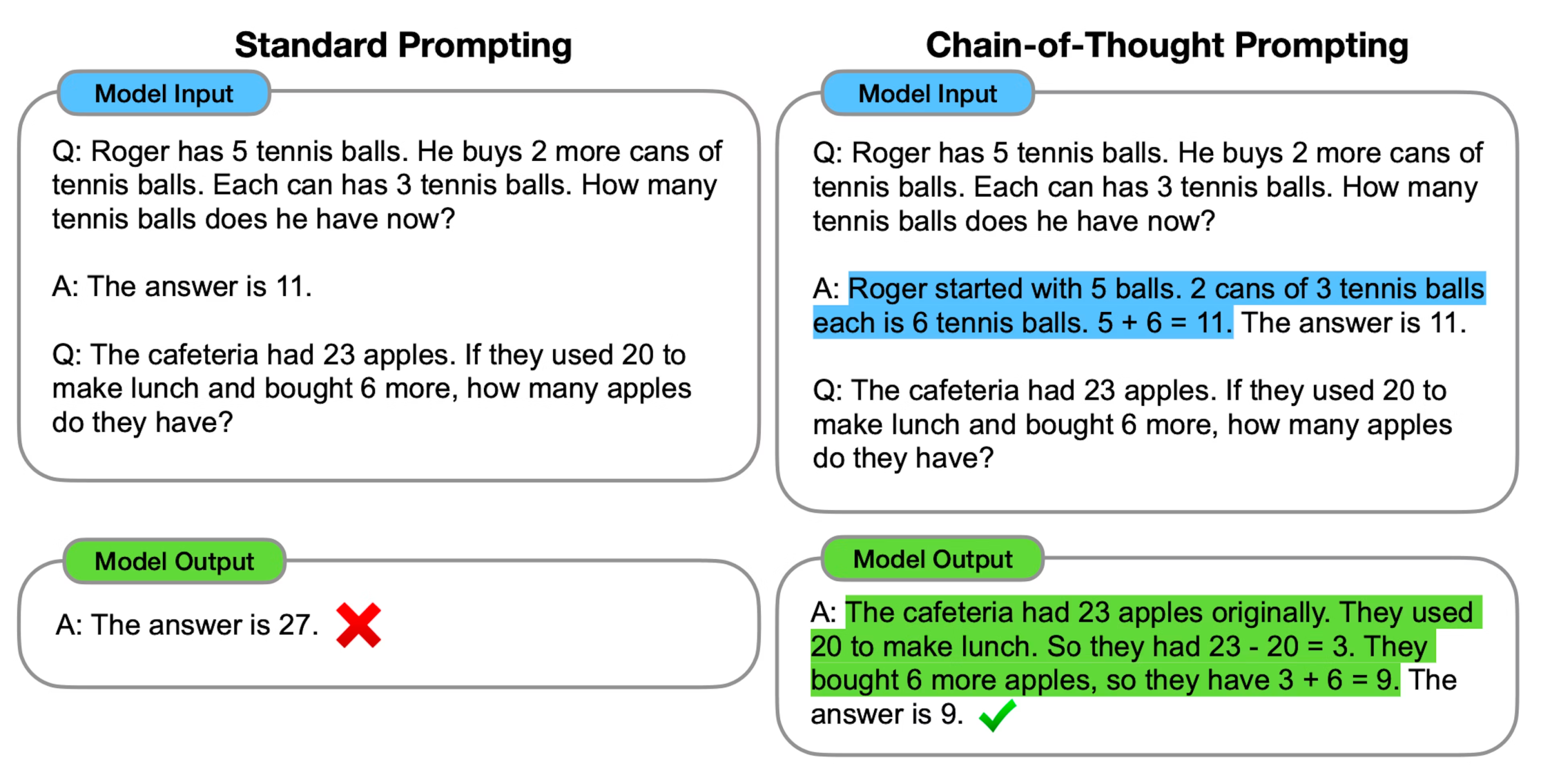
Personally, what concerns me more is the significant increase in token usage by the o1 model when addressing the same problems. Given that users, particularly professional API users, are billed based on token usage, this becomes critical. Reports suggest that in the same scenarios, the token consumption for Chain of Thought is tens or even hundreds of times higher, yet the quality of o1’s responses does not show substantial improvement over GPT-4o for many tasks.
In our daily lives and work, only about 5% of our activities are consciously controlled, while 95% are driven by the unconscious mind (i.e., activities controlled by the subconscious). Most of our day-to-day actions are automated and stored in the subconscious, allowing us to perform tasks without needing complex, energy-draining logical reasoning to instruct each muscle on how to open a door or drink water, or to deeply analyze the pros and cons of common goods before making everyday decisions. In most cases, even without a complete chain of thought, the subconscious helps us quickly open doors, drink water, and choose products we prefer. Although the human brain accounts for only about 2% of body weight, it consumes roughly 20% of the body’s energy, with reasoning being a significant contributor to this energy consumption.

According to OpenAI, we can think of GPT-4o as akin to the subconscious, and the o1 model as the prefrontal cortex, the logical brain. In many tasks, while the traditional GPT-4o may not deeply understand the logic behind a result or follow a clear chain of reasoning, however, the results it provides are often good enough. In contrast, the o1 model conducts a full logical analysis, breaks down tasks into smaller subtasks, and completes them sequentially, yet the resulting improvement in quality is often marginal. Meanwhile, the increased token usage means more energy consumption.
The question is how do we define these “many tasks“? We might draw inspiration from the division of labor in the brain: delegate less critical tasks to models like GPT-4o while assigning more complex reasoning to models like o1. However, the challenge lies in the fact that the boundary between conscious and subconscious processes isn’t absolute—they often influence and collaborate — and in the classification of reasoning levels for different tasks. In-depth neuroscience research may offer valuable insights.
As we look toward larger-scale AI applications in the future, balancing the consumption of computational resources with reasoning capability, and determining when to use a reasoning-focused model versus a model that delivers results without deep reasoning, will inevitably become an important question.

