Currently, models like OpenAI’s GPT, Anthropic’s Claude, and Meta AI’s LLaMA have achieved over 90% accuracy on the GSM8K dataset. But how do they accomplish this? Is it through memorization of data and problems, or do they truly understand the content of the questions?
GSM8K, short for “Grade School Math 8K,” comprises 8,000 math problems based on elementary school-level mathematics, covering basic arithmetic, geometry, algebra, and more. Each issue comes with detailed step-by-step solutions and final answers. The problems are described in natural language, making this dataset an ideal tool for testing a language model’s ability to understand and solve math problems.
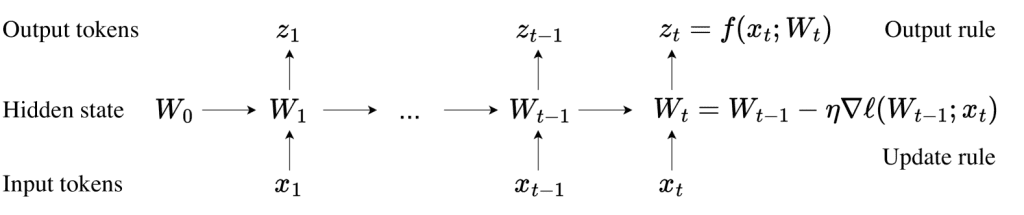
In a recent study, the authors designed experiments from scratch, avoiding data contamination to test the reasoning abilities of language models in a purer form. They automatically generated various math problems encompassing different types of arithmetic and reasoning challenges. The generated problems ranged from simple addition and subtraction to more complex multi-step reasoning tasks. This approach allows for controlled variables and tests the models’ performance across different difficulty levels and problem types. The study included new problems requiring multi-step reasoning and cross-question reasoning, which the models had never encountered in training, to determine whether the models possess genuine reasoning abilities rather than merely extracting information from training data. The researchers also employed probing techniques to monitor the models’ internal activation states during training, revealing how models handle and store intermediate reasoning steps.
The experiments demonstrated that models can correctly solve 99% of familiar problem types. When confronted with never-before-seen complex math problems, the models generated reasonable answers, showing some level of reasoning capability. This suggests that the models aren’t merely relying on memorization but possess some reasoning mechanisms. However, when dealing with long-chain reasoning problems, the models often lost information midway or made errors in certain steps. This indicates that current models still have limitations in handling long-chain and complex reasoning tasks, particularly in maintaining the integrity of the reasoning chain. Probing techniques revealed that the models’ internal activation states during problem-solving reflected a form of logical reasoning process rather than simple memory retrieval.
In the largely opaque internal processes of large language models, this experiment convincingly demonstrates that they do more than just remember training data and generate answers—they genuinely engage in logical reasoning.