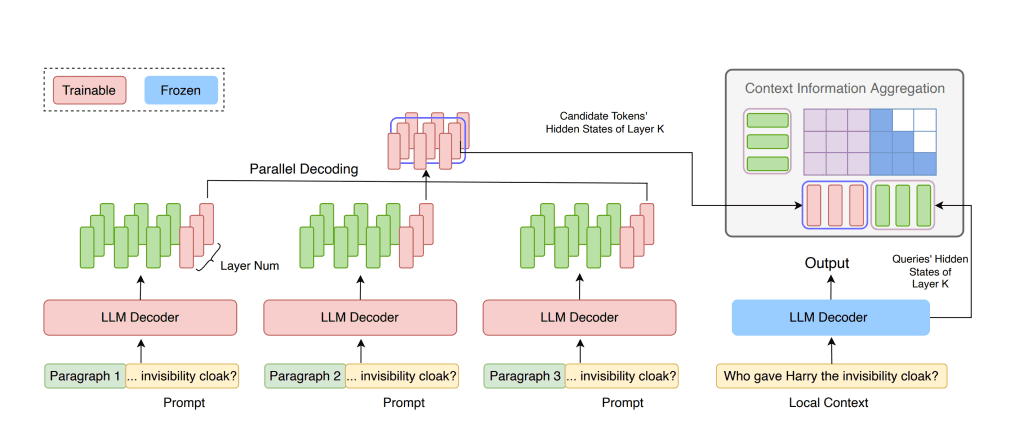
Scaling LLMs for Long Texts with FocusLLM
In traditional Transformer architectures, the computational complexity grows quadratically (O(L²)) with the length of the sequence, making it resource-intensive to process long sequences. This high demand for resources makes it impractical to extend context length directly. Even when fine-tuned on longer sequences, LLMs often struggle with extrapolation, failing to perform well on sequences longer than
Scaling LLMs for Long Texts with FocusLLM Read More »
Paper Skimming