A Comprehensive Summary of Extrinsic Hallucinations in LLMs.
A Comprehensive Summary of Extrinsic Hallucinations in LLMs. Read More »
Posts🔍 Exciting developments in the AI space: Mistral AI has unveiled its latest model, Mistral Large 2, boasting 123 billion parameters and a 128k context window. This model excels in code generation, mathematics, and multilingual support, making it a game-changer for complex business applications. It promises unmatched accuracy and performance through La Plateforme and major
Large Enough — Mistral Large 2 released Read More »
Articles, Posts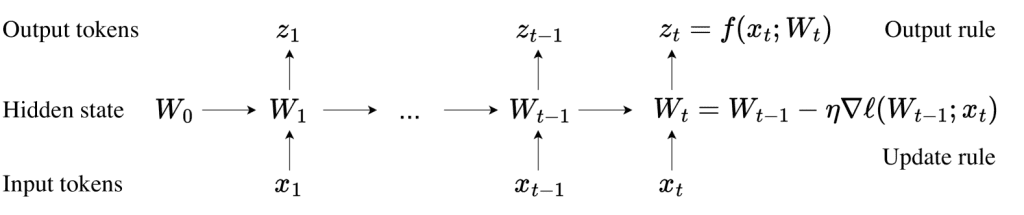
This research paper shows that TTT-Linear outperforms Mamba and Transformer in handling contexts as long as 32k. (See the card below) A self-supervised loss function on each test sequence reduces the likelihood of information forgetting in long sequences. Will the Test-Time Training(TTT) solve the problem of forgetting information in long sequences? As for the algorithm:
Test-Time Training — Is It an Alternative to Transformer? Read More »
Research Highlights“The world has long suffered under Nvidia’s dominance.”😂
Ultra Accelerator Link (UALink) Promoter Group Fromed Read More »
PostsThis recent study utilized various metrics to evaluate the similarity between different neural network representations, analyzing diverse architectures, training objectives, and data modalities. The findings reveal that different models, regardless of their architecture or objectives, can achieve aligned representations, and this alignment improves with model scale and performance. One key aspect of our research was
Breaking Imaginative Limits in Neural Network Alignment Read More »
Articles, Posts